Discover Global System Analysis & Services Administration Solution.
An AI-Driven Site Reliability Engineering Solution
our R&D Native & modular 360° Net-DevOps Solution

WHAT YOU WILL DO WITH NKINDA GSA
NKINDA GSA is a local/external SaaS for :
1. IT Cartography like Mega Hopex
2. Service Monitoring like ServiceNow
3. Alarm collection like OpenNMS
4. Project Management like Jira
5. Work collaboration like Confluence
6. ERP like SAP
7. Innovation new in the world
Industrialization of System/Network
> KPI deep checks and KPI Improvement
> deep checks & preventive maintenance
> Live deep troubleshooting
> change management
> deep checks & System/Network cartography
BACKGROUND
Efficient incident and breakdown management is critical in highly regulaled and competitive sectors such as banking, finance, the electromechanical industry, IT and telecommunications. In these fields, mean-time-to-repair ( MTTR ) and meantime-between-failures ( MTBF ) are key performance indicators that have a direct impact on service reliability, customer satisfaction and, ultimately, on company profitability, and SLAs ( Service Level Agreements ).
A dedicated log collection and analysis tool can play a crucial role in optimizing the indicators, providing an in depth understanding of system and system performance and facilitating rapid incident resolution.
NKINDA GSA is an advanced site reliability solution software, designed to ensure unparalleled system availability and performance.
This solution offers a competitive edge through its sophisticated alarm analysis and grading, proactive fault detection, and extensive fault resolution libraries along with root cause and reporting tools all imbedded in one box. By integrating state-of-the-art Site Reliability Engineering (SRE) / NetOps practices, the solution is tailored to meet the evolving demands of modern network operations within the Customer Network scope.
For a forward-thinking and innovation-driven company, adopting this cutting-edge software is essential to maintain its leadership in network operations and managed services. The solution not only addresses critical operational key performance indicators but also fosters a culture of continuous learning and improvement. By leveraging this software, the customer can enhance its operational efficiency, minimize downtime, and stay ahead in the competitive landscape of network technology.
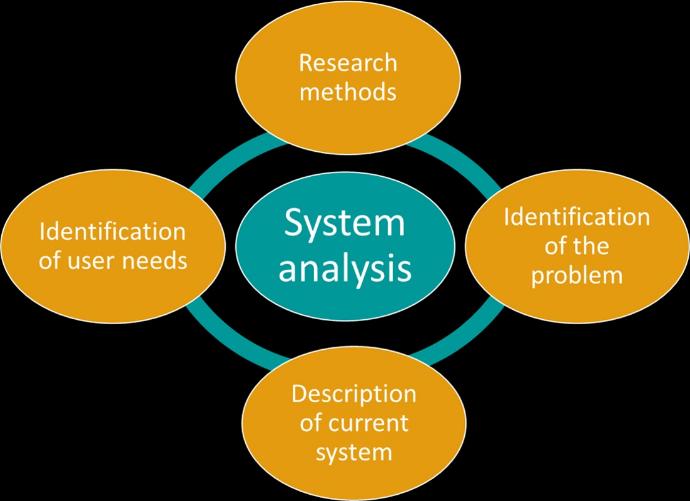
GSA objectives
The primary objectives of the GSA site reliability solution are to:
- Ensure 100% system availability.
- Provide advanced alarm analysis and grading.
- Detect and resolve faults efficiently.
- Utilize historical fault resolution libraries for fast resolution of recurrent issues.
- Integrate modern SRE practices.
- Address critical SRE operational KPIs such as Mean Time to Detect (MTTD), Mean Time to Resolve (MTTR), and others.
- Ensure interoperability across all IT/Telecom-related domains.
- Facilitate orchestrated bulk system changes with minimum to zero downtime.
- Support network planning and optimization and performance tuning.
- Provide performance analysis with real-time visualization and KPI tracking

Alarm analysis and grading
The solution will incorporate an intelligent alarm analysis system capable of:
• Analyzing incoming alarms and assigning severity grades.
• Reducing false positives through machine learning algorithms.
• Prioritizing alarms based on impact and urgency.
• Help the front office do perform preliminary L1 fault resolution tasks by making use of stored root cause analysis from past experiences.

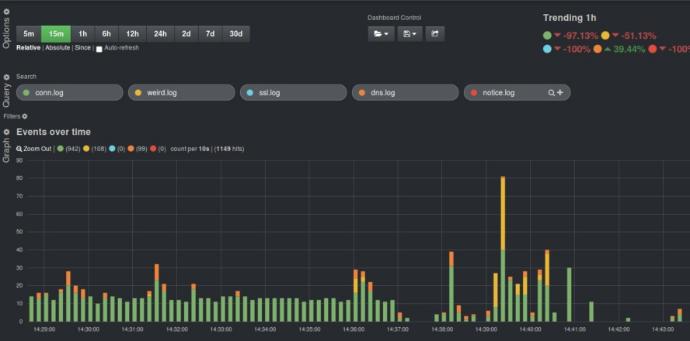
Realtime T-Shoot and Fault Detection
The system will:
• Continuously monitor system performance.
• Allow for Realtime issue T-Shoot during incidence and problem handling.
• Identify anomalies and potential faults in real-time.
• Use predictive analytics to foresee possible system failures.
Fault Resolution Libraries
The solution will maintain a comprehensive library of past faults and resolutions, allowing for:
• Quick reference to historical data for faster resolution.
• Automated application of proven solutions to recurring issues.
• Continuous updating and optimization of the fault resolution library.

Task automation engine
The solution will be ideal in handling repetitive tasks and processes efficiently.
• Task Automation: The system has an AI powered engine to automate repetitive and manual tasks, improving efficiency and reducing human workload and ME (Man-made Error) .
• Process Automation: This one is capable of automating repeated workflows, enhancing productivity, and ensuring consistency in day to day tasks

Analytics and Reporting engine
The solution will also be able to perform
• Data Analysis: Analysis on large datasets to uncover patterns, trends, and insights that may not be evident to humans.
• Reporting: Some reports can be generated based on analyzed data trends. This can also be used to do predictive decision making and root cause determination in incident handling.
SRE / NetOps Practices
The solution will integrate modern SRE practices, including:
• Automated incident response and resolution.
• Continuous performance monitoring and improvement.
• Reliability engineering metrics (SLAs, SLOs, SLIs).
• Post-incident reviews and blameless retrospectives.
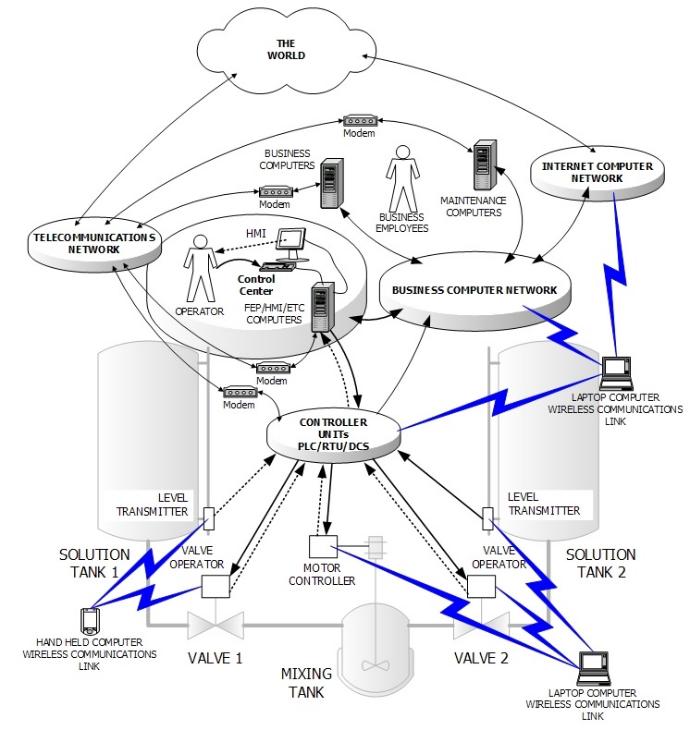
Interoperability
The solution will ensure ease of use and integration across all various IT domains, including it also comes along with portable executable files.
• IT INFRASTRUCTURE
• CORE NETWORK
• RAN (Radio Access Network)
• PACKET SWITCHING
• INTELLIGENT NETWORK
• VALUE ADDED SERVICES
• IP / DATACOMMS NETWORKS
This interoperability will allow seamless integration and usage across different technological environments and systems in all domains
Orchestration
The solution will support task and process orchestration to facilitate bulk system changes, ensuring:
• Automated deployment and configuration management.
• Consistent and error-free updates across multiple systems.
• Streamlined processes for large-scale changes and migrations.
Network planning and Optimization
The solution will assist in future network planning and optimization by:
• Providing detailed performance analytics and historical data.
• Supporting predictive modeling for capacity planning.
• Offering tools for network design and optimization based on current and projected needs.
Intelligent operations with Nkinda AIOps modules
In an environment where the complexity of network infrastructures and IT systems continues to grow, proactive incident management becomes crucial. This is where NKINDA GSA stands out with its nkinda AIOps (Artificial Intelligence for IT Operations) module, integrating artificial intelligence and machine learning to revolutionize IT operations.
Using AI , NKINDA GSA enables automated, predictive analysis of the vast volumes of data generated by systems. By reliably detecting abnormal patterns and learning from past incidents, nkinda AIOps simplifies the role of SRE engineers. This frees them from repetitive, manual tasks, allowing them to focus on innovation and solving strategic business challenges. Intelligent operations automation improves responsiveness, reduces downtime, and ensures proactive incident resolution, even before performance is affected.
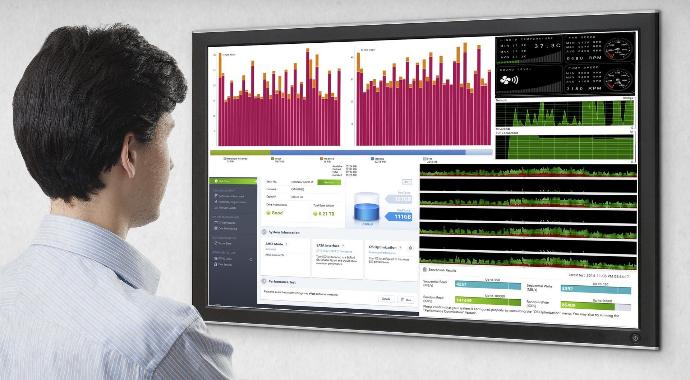
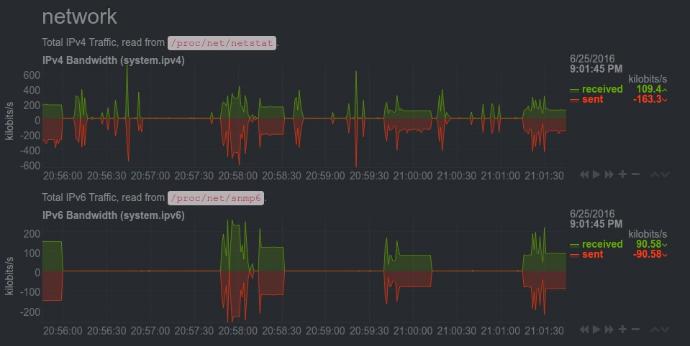
Performance analysis and Visualisations
The solution will include a performance analysis tool that:
• Provides real-time system monitoring.
• Tracks key performance indicators (KPIs) and generates reports.
• Includes plugins for popular visualization tools (e.g., Grafana, Kibana, ...) to offer intuitive and customizable dashboards. All what
DEVELOPMENT / INTEGRATION PROCESSES
Week 1
- Audit & analysis of existing
situation
- Identification & elaboration of
requirements.
Week 2
Start of dev /+ integration
weekend delivery.
Week 3
Validation tests & Delivery
###
Evaluation & observation
TREE (3) WEEKS of DEV / Core Module.

Success Stories-Telecom
-Performance analysis of web services
-Online Charging System integration support
-Collect & provide tuning LOG Tshoot Analysis
-Integration on Open service Gateway
- Integration support for Backbone IP/MPLS
-
Integration support for Core Network

Integration of Nkinda GSA
-Three Possibilities
- portable software
- On premise SaaS
-
Cloud SaaS
Hardware specification
8 cores CPU
32 GB RAM
Disk: 2 TB

Contracts and confidentiality
NDA:Confidentiality agreement
Sale of software licenses
Technical support contract

Phased approach
The implementation will follow a phased approach:
• Phase 1: Assessment and Planning - Assess current systems in all domains, define requirements, and plan implementation.
• Phase 2: Integration and deployment – integration and deployment of the site reliability solution software across all domains.
• Phase 3: Testing and Validation - Conduct rigorous testing to validate functionality and performance.
• Phase 4: Training and Continues Integration and Deployment - Train staff and deploy the solution across the organization.
• Phase 5: Monitoring and Optimization - Monitor performance and optimize the solution based on feedback
Expected Outcome
• Improved System Availability - Achieve near 100% uptime.
• Efficient Fault Management - Faster detection and resolution of issues.
• Enhanced Performance Monitoring - Real-time insights into system performance.
• Proactive Incident Management - Predict and prevent potential incidents.
• Continuous Improvement - Leverage historical data for ongoing optimization.
• Seamless Interoperability - Smooth integration across various IT domains.
• Effective Orchestration - Simplified bulk system changes.
• Optimized Network Planning - Data-driven network design and optimization.
• Comprehensive Performance Analysis - Real-time monitoring and KPI tracking with visualization tools.
Critical GSA Solution Operational KPI
The solution will address several crucial SRE operational KPIs to ensure optimal performance and reliability, including:
• Mean Time to Detect (MTTD): The average time taken to detect an incident. Reducing MTTD helps in quicker identification of issues.
• Mean Time to Resolve (MTTR): The average time taken to resolve an incident after it has been detected. Lower MTTR indicates faster resolution capabilities.
• Service Level Indicators (SLIs): Metrics that measure the performance of a service (e.g., latency, error rate, throughput).
• Service Level Objectives (SLOs): Targets set for SLIs that define acceptable performance levels.
• Service Level Agreements (SLAs): Formal agreements that set expectations for service performance between service providers and customers.
• Change Failure Rate: The percentage of changes that result in degraded service or require remediation. Lower rates indicate more successful changes.
• Error Budget: The allowable amount of downtime or errors within a specific period, derived from SLOs.
• Incident Rate: The frequency of incidents occurring within a specific timeframe. Monitoring this helps in understanding system stability.
• Availability: The percentage of time the system is operational and available. High availability is crucial for user satisfaction.

Evaluation Criteria
The success of the PoC will be evaluated based on:
• System Uptime - Measurement of system availability.
• Alarm Prioritization Accuracy - Reduction in false positives and accurate grading of alarms.
• Fault Resolution Time - Reduction in the time taken to resolve faults.
• User Feedback - Feedback from system administrators and users.
• Performance Metrics - Improvement in key performance indicators (KPIs) such as MTTD, MTTR, SLIs, SLOs, SLAs, Change Failure Rate, Error Budget, Incident Rate, and Availability.
• Interoperability - Successful integration and usage across various IT/ network domains.
• Orchestration Effectiveness - Efficiency and accuracy of bulk system changes with zero tolerance to downtime
• Network Planning Optimization - Quality of insights and improvements in network planning.
• Visualization and Analysis - Effectiveness of real-time monitoring and KPI tracking through visualization tools
