Découvrez la solution Global System Analysis & Services Administration.
Une solution d'ingénierie de la fiabilité des sites pilotée par l'IA
notre solution Net-DevOps 360° modulaire et native pour la R&D

CE QUE VOUS FEREZ AVEC NKINDA GSA
NKINDA GSA est un SaaS local/externe pour :
1. Cartographie informatique comme Mega Hopex
2. Surveillance des services comme ServiceNow
3. Collecte d'alarmes comme OpenNMS
4. Gestion de projet comme Jira
5. Collaboration au travail comme Confluence
6. ERP comme SAP
7. Innovation nouvelle dans le monde
Industrialisation du système/réseau
> Contrôles approfondis des KPI et amélioration des KPI
> Contrôles approfondis et maintenance préventive
> Dépannage approfondi en direct
> gestion du changement
> vérifications approfondies et cartographie du système/réseau
CONTEXTE
Une gestion efficace des incidents et des pannes est essentielle dans les secteurs hautement réglementés et compétitifs tels que la banque, la finance, l'industrie électromécanique, l'informatique et les télécommunications. Dans ces domaines, le temps moyen de réparation (MTTR) et le temps moyen entre deux pannes (MTBF) sont des indicateurs de performance clés qui ont un impact direct sur la fiabilité du service, la satisfaction du client et, en fin de compte, sur la rentabilité de l'entreprise et les accords de niveau de service (SLA).
Un outil dédié à la collecte et à l'analyse des journaux peut jouer un rôle crucial dans l'optimisation des indicateurs, en fournissant une compréhension approfondie du système et de ses performances et en facilitant la résolution rapide des incidents.
NKINDA GSA est une solution logicielle avancée de fiabilité des sites, conçue pour assurer une disponibilité et une performance inégalées des systèmes.
Cette solution offre un avantage concurrentiel grâce à une analyse et un classement sophistiqués des alarmes, une détection proactive des défaillances, des bibliothèques étendues de résolution des défaillances ainsi que des outils d'analyse des causes profondes et de reporting, le tout intégré dans un seul et même boîtier. En intégrant des pratiques de pointe en matière d'ingénierie de la fiabilité des sites (SRE) et de NetOps, la solution est conçue pour répondre aux exigences évolutives des opérations de réseau modernes dans le cadre du réseau du client.
Pour une entreprise tournée vers l'avenir et l'innovation, l'adoption de ce logiciel de pointe est essentielle pour maintenir son leadership en matière d'opérations de réseau et de services gérés. La solution ne se contente pas de prendre en compte les indicateurs clés de performance opérationnelle, mais favorise également une culture de l'apprentissage et de l'amélioration continus. En tirant parti de ce logiciel, le client peut améliorer son efficacité opérationnelle, minimiser les temps d'arrêt et garder une longueur d'avance dans le paysage concurrentiel de la technologie des réseaux.
Objectifs de la GSA
Les principaux objectifs de la solution de fiabilité du site de la GSA sont les suivants :
- Assurer la disponibilité du système à 100 %.
- Fournir une analyse et un classement avancés des alarmes.
- Détecter et résoudre les problèmes de manière efficace.
- Utiliser les bibliothèques de résolution de pannes historiques pour résoudre rapidement les problèmes récurrents.
- Intégrer des pratiques SRE modernes.
- Aborder les KPI opérationnels critiques de la SRE, tels que le temps moyen de détection (MTTD), le temps moyen de résolution (MTTR), etc.
- Assurer l'interopérabilité dans tous les domaines liés aux technologies de l'information et des télécommunications.
- Faciliter les changements de système en masse orchestrés avec un temps d'arrêt minimal, voire nul.
- Soutenir la planification et l'optimisation du réseau ainsi que le réglage des performances.
- Fournir une analyse des performances avec une visualisation en temps réel et un suivi des indicateurs clés de performance.

Analyse et classement des alarmes
La solution comprendra un système intelligent d'analyse des alarmes capable de :
- Analyser les alarmes entrantes et attribuer des niveaux de gravité.
- Réduire les faux positifs grâce à des algorithmes d'apprentissage automatique.
- Prioriser les alarmes en fonction de l'impact et de l'urgence.
- Aider le front office à effectuer des tâches préliminaires de résolution des pannes en L1 en utilisant l'analyse des causes profondes stockées dans les expériences passées.

Détection en temps réel des erreurs et des défauts
Le système:
- Contrôler en permanence les performances du système.
- Permettre la résolution des problèmes en temps réel lors de l'incidence et du traitement des problèmes.
- Identifier les anomalies et les défauts potentiels en temps réel.
- Utiliser l'analyse prédictive pour prévoir les défaillances possibles du système.
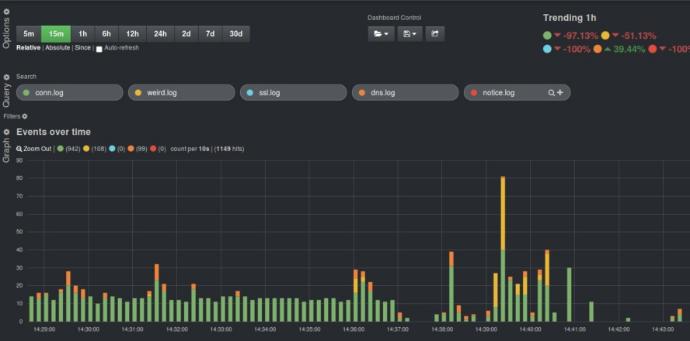
Bibliothèques de résolution des défaillances
La solution conservera une bibliothèque complète des fautes et des résolutions antérieures, ce qui permettra de:
- une référence rapide aux données historiques pour une résolution plus rapide
- L'application automatisée de solutions éprouvées à des problèmes récurrents.
- la mise à jour et l'optimisation permanentes de la bibliothèque de résolution des problèmes.

Moteur d'automatisation des tâches
La solution sera idéale pour gérer efficacement les tâches et les processus répétitifs.
- Automatisation des tâches : Le système dispose d'un moteur alimenté par l'IA pour automatiser les tâches répétitives et manuelles, améliorant ainsi l'efficacité et réduisant la charge de travail humaine et les erreurs d'origine humaine (ME).
- Automatisation des processus : Ce système est capable d'automatiser les flux de travail répétés, d'améliorer la productivité et d'assurer la cohérence des tâches quotidiennes.

Moteur d'analyse et de rapport
La solution sera également en mesure d'effectuer
- Analyse de données : L'analyse de grands ensembles de données pour découvrir des modèles, des tendances et des informations qui ne sont pas forcément évidents pour les humains.
- Rapports : Certains rapports peuvent être générés sur la base des tendances des données analysées. Cela peut également être utilisé pour prendre des décisions prédictives et déterminer la cause première d'un incident.
Pratiques SRE / NetOps
La solution intégrera des pratiques SRE modernes, notamment
- la réponse et la résolution automatisées des incidents
- le contrôle et l'amélioration continus des performances
- Mesures d'ingénierie de la fiabilité (SLA, SLO, SLI).
- Examens post-incidents et rétrospectives sans reproche.
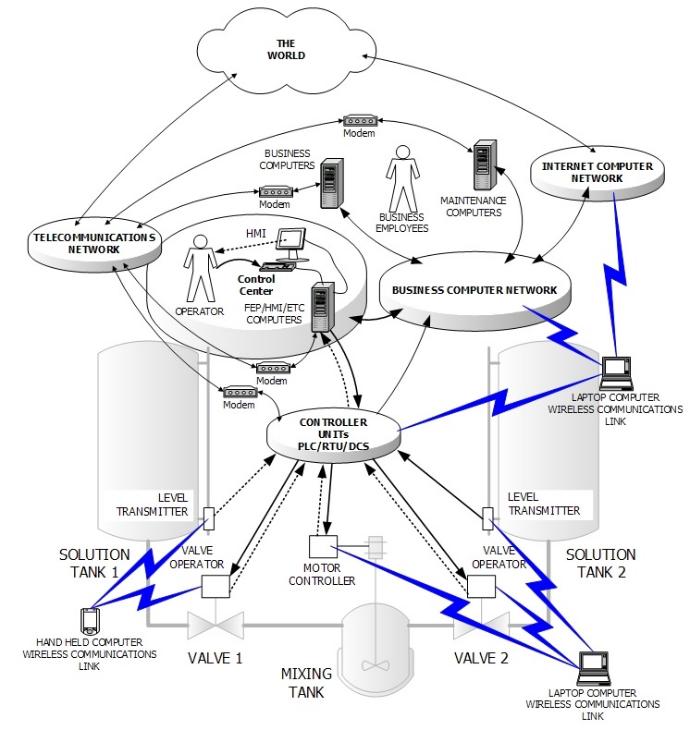
Interopérabilité
La solution assurera une facilité d'utilisation et d'intégration dans tous les domaines informatiques, y compris les fichiers exécutables portables.
- INFRASTRUCTURE INFORMATIQUE
- RÉSEAU DE BASE
- RAN (réseau d'accès radio)
- COMMUTATION DE PAQUETS
- RÉSEAU INTELLIGENT
- SERVICES À VALEUR AJOUTÉE
- RÉSEAUX IP / DATACOMMS
Cette interopérabilité permettra une intégration et une utilisation transparentes dans différents environnements et systèmes technologiques dans tous les domaines.
Orchestration
La solution prendra en charge l'orchestration des tâches et des processus afin de faciliter les changements de système en masse, en garantissant :
- l'automatisation du déploiement et de la gestion de la configuration
- Des mises à jour cohérentes et sans erreur sur plusieurs systèmes.
- des processus rationalisés pour les changements et les migrations à grande échelle.
Planification et optimisation du réseau
La solution aidera à la planification et à l'optimisation futures du réseau en
- Fournissant des analyses de performance détaillées et des données historiques.
- En prenant en charge la modélisation prédictive pour la planification de la capacité.
- Proposant des outils pour la conception et l'optimisation du réseau en fonction des besoins actuels et prévus.
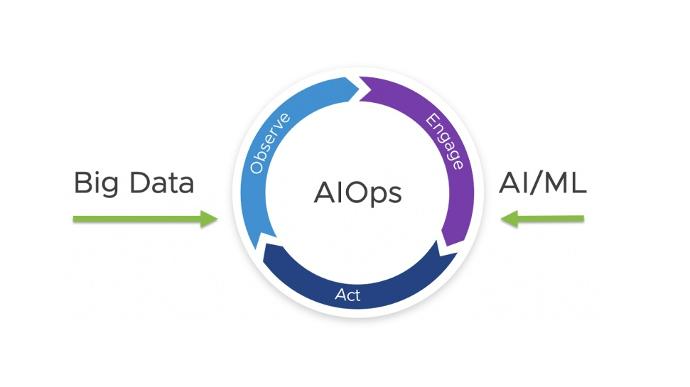
Opérations intelligentes avec les modules AIOps de Nkinda
Dans un environnement où la complexité des infrastructures réseaux et des systèmes informatiques ne cesse de croître, la gestion proactive des incidents devient cruciale. C'est là que NKINDA GSA se distingue avec son module nkinda AIOps (Artificial Intelligence for IT Operations), intégrant l'intelligence artificielle et l'apprentissage automatique pour révolutionner les opérations informatiques.Grâce à l'IA, NKINDA GSA permet une analyse automatisée et prédictive des vastes volumes de données générés par les systèmes. En détectant de manière fiable les schémas anormaux et en tirant des leçons des incidents passés, nkinda AIOps simplifie le rôle des ingénieurs SRE. Ils sont ainsi libérés des tâches répétitives et manuelles, ce qui leur permet de se concentrer sur l'innovation et la résolution des défis stratégiques de l'entreprise. L'automatisation intelligente des opérations améliore la réactivité, réduit les temps d'arrêt et garantit une résolution proactive des incidents, avant même que les performances ne soient affectées.
Analyse des performances et visualisations
La solution comprendra un outil d'analyse des performances qui
- assure la surveillance du système en temps réel
- Suit les indicateurs clés de performance (KPI) et génère des rapports.
- Inclut des plugins pour les outils de visualisation populaires (par exemple, Grafana, Kibana, ...) afin d'offrir des tableaux de bord intuitifs et personnalisables. Tout ce que
PROCESSUS DE DÉVELOPPEMENT / D'INTÉGRATION
Semaine 1
- Audit et analyse de la situation existante
situation existante
- Identification et élaboration des
exigences.
Semaine 2
Début de l'intégration dev /+
livraison le week-end.
Semaine 3
Tests de validation et livraison
###
Évaluation et observation
TREE (3) SEMAINES de DEV / Module de base.

Histoires de réussite - Télécoms
-Analyse des performances des services web
-Soutien à l'intégration du système de facturation en ligne
-Collecte et fourniture d'analyses de tuning LOG Tshoot
-Intégration sur les passerelles de services ouvertes
- Support d'intégration pour Backbone IP/MPLS
- Support d'intégration pour le réseau central

Intégration de Nkinda GSA
-Trois possibilités
- logiciel portable
- SaaS sur site
-
Cloud SaaS
Spécifications matérielles
Processeur à 8 cœurs
32 GO DE RAM
Disque : 2 TB

Contrats et confidentialité
NDA : Accord de confidentialité
Vente de licences de logiciels
Contrat d'assistance technique

Approche progressive
La mise en œuvre se fera par étapes :
- Phase 1 : Évaluation et planification - Évaluer les systèmes actuels dans tous les domaines, définir les besoins et planifier la mise en œuvre.
- Phase 2 : Intégration et déploiement - intégration et déploiement du logiciel de la solution de fiabilité des sites dans tous les domaines.
- Phase 3 : Essais et validation - Effectuer des essais rigoureux pour valider les fonctionnalités et les performances.
- Phase 4 : Formation et poursuite de l'intégration et du déploiement - Former le personnel et déployer la solution dans l'ensemble de l'organisation.
- Phase 5 : Surveillance et optimisation - Surveiller les performances et optimiser la solution en fonction du retour d'information.
Résultats attendus
- Amélioration de la disponibilité du système - Atteindre un temps de fonctionnement proche de 100 %.
- Gestion efficace des pannes - Détection et résolution plus rapides des problèmes.
- Surveillance améliorée des performances - Aperçu en temps réel des performances du système.
- Gestion proactive des incidents - Prévoir et prévenir les incidents potentiels.
- Amélioration continue - Exploitation des données historiques pour une optimisation continue.
- Interopérabilité transparente - Intégration transparente dans les différents domaines informatiques.
- Orchestration efficace - Simplification des changements de système en masse.
- Planification optimisée du réseau - Conception et optimisation du réseau basées sur les données.
- Analyse complète des performances - Surveillance en temps réel et suivi des indicateurs clés de performance avec des outils de visualisation.
KPI opérationnels critiques de la solution GSA
La solution prendra en compte plusieurs KPI opérationnels cruciaux pour les SRE afin d'assurer une performance et une fiabilité optimales, notamment :
- Le temps moyen de détection (MTTD) : Le temps moyen nécessaire à la détection d'un incident. La réduction du MTTD permet d'identifier plus rapidement les problèmes.
- Temps moyen de résolution (MTTR) : Le temps moyen nécessaire pour résoudre un incident après sa détection. Un MTTR inférieur indique des capacités de résolution plus rapides.
- Indicateurs de niveau de service (SLI) : Les indicateurs qui mesurent la performance d'un service (par exemple, la latence, le taux d'erreur, le débit).
- Objectifs de niveau de service (SLO) : Cibles fixées pour les indicateurs de niveau de service qui définissent les niveaux de performance acceptables.
- Accords de niveau de service (SLA) : Accords formels qui définissent les attentes en matière de performance des services entre les fournisseurs de services et les clients.
- Taux d'échec des changements : Le pourcentage de changements qui entraînent une dégradation du service ou qui nécessitent une remédiation. Des taux plus bas indiquent des changements plus réussis.
- Budget d'erreur : La quantité admissible de temps d'arrêt ou d'erreurs au cours d'une période spécifique, dérivée des SLO.
- Taux d'incidents : La fréquence des incidents survenant dans un délai spécifique. Le suivi de ce taux aide à comprendre la stabilité du système.
- Disponibilité : Le pourcentage de temps pendant lequel le système est opérationnel et disponible. Une disponibilité élevée est cruciale pour la satisfaction des utilisateurs.

Critères d'évaluation
La réussite du PoC sera évaluée sur la base des éléments suivants :
- Temps de disponibilité du système - Mesure de la disponibilité du système.
- Précision de la hiérarchisation des alarmes - Réduction des faux positifs et classement précis des alarmes.
- Temps de résolution des pannes - Réduction du temps nécessaire à la résolution des pannes.
- Rétroaction des utilisateurs - Rétroaction des administrateurs et des utilisateurs du système.
- Indicateurs de performance - Amélioration des indicateurs de performance clés (KPI) tels que MTTD, MTTR, SLI, SLO, SLA, taux d'échec des changements, budget d'erreur, taux d'incident et disponibilité.
- Interopérabilité - Intégration et utilisation réussies dans divers domaines informatiques/réseaux.
- Efficacité de l'orchestration - Efficacité et précision des changements de système en masse avec une tolérance zéro pour les temps d'arrêt.
- Optimisation de la planification du réseau - Qualité des informations et améliorations apportées à la planification du réseau.
- Visualisation et analyse - Efficacité de la surveillance en temps réel et du suivi des indicateurs clés de performance grâce à des outils de visualisation.
