Descubra a Solução de Administração de Serviços e Análise Global de Sistemas.
Uma solução de engenharia de fiabilidade de sítios orientada por IA
a nossa solução de I&D nativa e modular de 360° Net-DevOps

O QUE VAI FAZER COM NKINDA GSA
NKINDA GSA é um SaaS local/externo para :
1. Cartografia informática como o Mega Hopex
2. Monitorização de serviços como o ServiceNow
3. Coleção de alarmes como o OpenNMS
4. Gestão de projectos como o Jira
5. Colaboração no trabalho como o Confluence
6. ERP como o SAP
7. Inovação inédita no mundo
Industrialização do sistema/rede
> Controlos aprofundados dos KPI e melhoria dos KPI
> Controlos aprofundados e manutenção preventiva
> Resolução de problemas em direto
> gestão da mudança
> verificações profundas e cartografia do sistema/rede
ANTECEDENTES
EA gestão eficiente de incidentes e avarias é fundamental em sectores altamente regulamentados e competitivos, como a banca, as finanças, a indústria eletromecânica, as TI e as telecomunicações. Nestes domínios, o tempo médio de reparação (MTTR) e o tempo médio entre falhas (MTBF) são indicadores-chave de desempenho que têm um impacto direto na fiabilidade do serviço, na satisfação do cliente e, em última análise, na rentabilidade da empresa e nos SLA (acordos de nível de serviço).
Uma ferramenta específica de recolha e análise de registos pode desempenhar um papel crucial na otimização dos indicadores, proporcionando uma compreensão aprofundada do desempenho do sistema e do sistema e facilitando a rápida resolução de incidentes.
NO NKINDA GSA é um software avançado de solução de fiabilidade de instalações, concebido para garantir uma disponibilidade e um desempenho sem paralelo do sistema.
Esta solução oferece uma vantagem competitiva através da sua sofisticada análise e classificação de alarmes, deteção proactiva de falhas e extensas bibliotecas de resolução de falhas, juntamente com ferramentas de causa raiz e de elaboração de relatórios, tudo integrado numa caixa. Ao integrar práticas avançadas de Engenharia de Fiabilidade do Local (SRE) / NetOps, a solução é adaptada para satisfazer as exigências em evolução das operações de rede modernas no âmbito da Rede do Cliente.
Para uma empresa com visão de futuro e orientada para a inovação, a adoção deste software de ponta é essencial para manter a sua liderança em operações de rede e serviços geridos. A solução não só aborda indicadores-chave de desempenho operacional críticos, como também promove uma cultura de aprendizagem e melhoria contínuas. Ao tirar partido deste software, o cliente pode aumentar a sua eficiência operacional, minimizar o tempo de inatividade e manter-se à frente no panorama competitivo da tecnologia de rede.
Objectivos da GSA
Os principais objectivos da solução de fiabilidade do sítio da GSA são os seguintes:
- Assegurar a disponibilidade do sistema a 100%.
- Fornecer análise e classificação avançadas de alarmes.
- Detetar e resolver as falhas de forma eficiente.
- Utilizar bibliotecas de resolução de falhas históricas para uma resolução rápida de problemas recorrentes.
- Integrar práticas modernas de SRE.
- Abordar os KPIs operacionais críticos do SRE, como o tempo médio de deteção (MTTD), o tempo médio de resolução (MTTR) e outros.
- Assegurar a interoperabilidade em todos os domínios relacionados com as TI/Telecom.
- Facilitar alterações orquestradas do sistema em massa com um tempo de inatividade mínimo ou nulo.
- Apoiar o planeamento e a otimização da rede e a afinação do desempenho.
- Fornecer análise de desempenho com visualização em tempo real e acompanhamento de KPI

Análise e classificação de alarmes
A solução incorporará um sistema inteligente de análise de alarmes capaz de:
• Analisar os alarmes recebidos e atribuir graus de gravidade.
• Reduzir os falsos positivos através de algoritmos de aprendizagem automática.
• Definição de prioridades para os alarmes com base no impacto e na urgência.
• Ajudar o front office a realizar tarefas preliminares de resolução de falhas L1, utilizando a análise de causas armazenadas de experiências anteriores.

T-Shoot em tempo real e deteção de falhas
O sistema irá:
• Monitorizar continuamente o desempenho do sistema.
• Permitir a resolução de problemas em tempo real durante a incidência e o tratamento de problemas.
• Identificar anomalias e potenciais falhas em tempo real.
• Utilizar a análise preditiva para prever possíveis falhas do sistema.
Bibliotecas de resolução de falhas
A solução manterá uma biblioteca abrangente de falhas e resoluções anteriores, permitindo:
• Referência rápida a dados históricos para uma resolução mais rápida.
• Aplicação automatizada de soluções comprovadas para problemas recorrentes.
• Atualização e otimização contínuas da biblioteca de resolução de falhas

Motor de automatização de tarefas
A solução será ideal para lidar com tarefas e processos repetitivos de forma eficiente.
• Automatização de tarefas: O sistema dispõe de um motor alimentado por IA para automatizar tarefas repetitivas e manuais, melhorando a eficiência e reduzindo a carga de trabalho humana e o ME (Man-made Error) .
• Automatização de processos: Este é capaz de automatizar fluxos de trabalho repetidos, aumentar a produtividade e garantir a consistência nas tarefas quotidianas

Mecanismo de análise e relatórios
A solução também será capaz de realizar
• Análise de dados: Análise de grandes conjuntos de dados para descobrir padrões, tendências e percepções que podem não ser evidentes para os seres humanos.
• Relatórios: Alguns relatórios podem ser gerados com base nas tendências dos dados analisados. Isto também pode ser utilizado para tomar decisões preditivas e determinar a causa principal no tratamento de incidentes.
Práticas SRE / NetOps
A solução integrará práticas modernas de SRE, incluindo:
• Resposta e resolução automatizadas de incidentes
• Controlo e melhoria contínuos do desempenho.
• Métricas de engenharia de fiabilidade (SLAs, SLOs, SLIs).
• Análises pós-incidente e retrospectivas sem culpa.
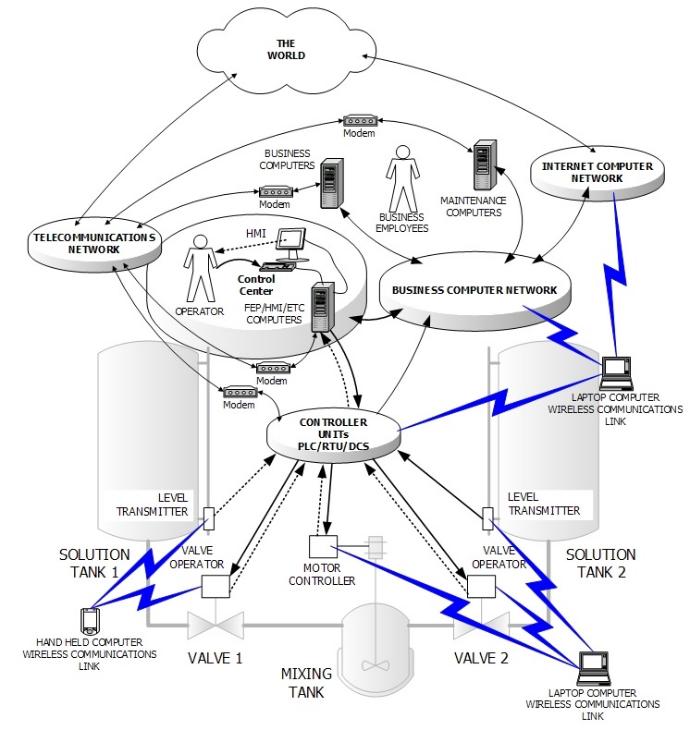
Interoperabilidade
A solução garantirá a facilidade de utilização e integração em todos os vários domínios de TI, incluindo também ficheiros executáveis portáteis.
• INFRA-ESTRUTURAS INFORMÁTICAS
• REDE DE NÚCLEOS
• RAN (Rede de acesso via rádio)
• COMUTAÇÃO DE PACOTES
• REDE INTELIGENTE
• SERVIÇOS DE VALOR ACRESCENTADO
• REDES IP / DATACOMMS
Esta interoperabilidade permitirá uma integração e utilização sem descontinuidades em diferentes ambientes e sistemas tecnológicos em todos os domínios
Orquestração
A solução apoiará a orquestração de tarefas e processos para facilitar as alterações em massa do sistema, garantindo:
• Implementação automatizada e gestão de configuração.
• Actualizações consistentes e sem erros em vários sistemas.
• Processos simplificados para alterações e migrações em grande escala.
Planeamento e otimização de redes
A solução ajudará no futuro planeamento e otimização da rede:
• Fornecimento de análises de desempenho pormenorizadas e dados históricos.
• Apoio à modelação preditiva para o planeamento da capacidade.
• Oferecer ferramentas para a conceção e otimização da rede com base nas necessidades actuais e previstas.
Operações inteligentes com os módulos Nkinda AIOps
Num ambiente em que a complexidade das infra-estruturas de rede e dos sistemas de TI continua a crescer, a gestão proactiva de incidentes torna-se crucial. É aqui que a NKINDA GSA se destaca com o seu módulo nkinda AIOps (Inteligência Artificial para Operações de TI), que integra a inteligência artificial e a aprendizagem automática para revolucionar as operações de TI.
Utilizando a IA, a NKINDA GSA permite uma análise automatizada e preditiva dos vastos volumes de dados gerados pelos sistemas. Ao detetar de forma fiável padrões anormais e aprender com incidentes passados, o nkinda AIOps simplifica o papel dos engenheiros SRE. Isto liberta-os de tarefas manuais e repetitivas, permitindo-lhes concentrarem-se na inovação e na resolução de desafios empresariais estratégicos. A automatização inteligente das operações melhora a capacidade de resposta, reduz o tempo de inatividade e assegura a resolução proactiva de incidentes, mesmo antes de o desempenho ser afetado.
Análise de desempenho e visualizações
A solução incluirá uma ferramenta de análise de desempenho que:
• Fornece monitorização do sistema em tempo real.
• Acompanha os indicadores-chave de desempenho (KPI) e gera relatórios.
• Inclui plugins para ferramentas de visualização populares (por exemplo, Grafana, Kibana, ...) para oferecer dashboards intuitivos e personalizáveis. Tudo o quet
PROCESSOS DE DESENVOLVIMENTO / INTEGRAÇÃO
Semana 1
- Auditoria e análise da situação atual
situação atual
- Identificação e elaboração de
requisitos.
Semana 2
Início da integração dev /+
entrega ao fim de semana.
Semana 3
Testes de validação e entrega
###
Avaliação e observação
TRÊS (3) SEMANAS de DEV / Módulo principal.

Histórias de sucesso-Telecom
-Análise do desempenho dos serviços Web
-Apoio à integração do sistema de carregamento em linha
-Recolha e fornecimento de análises de afinação LOG Tshoot
-Integração no Open Service Gateway
- Suporte de integração para Backbone IP/MPLS
-
Suporte de integração para a rede principal

Integração do Nkinda GSA
-Três possibilidades
- software portátil
- SaaS no local
-
Nuvem SaaS
Especificação de hardware
CPU de 8 núcleos
32 GB DE RAM
Disco: 2 TB

Contratos e confidencialidade
NDA: Acordo de confidencialidade
Venda de licenças de software
Contrato de assistência técnica

Abordagem faseada
A implementação seguirá uma abordagem faseada:
- Fase 1: Avaliação e Planeamento - Avaliar os sistemas actuais em todos os domínios, definir requisitos e planear a implementação.
- Fase 2: Integração e implementação - integração e implementação do software da solução de fiabilidade do site em todos os domínios.
- Fase 3: Testes e validação - Realização de testes rigorosos para validar a funcionalidade e o desempenho.
- Fase 4: Formação e Continuação da Integração e Implementação - Formar o pessoal e implementar a solução em toda a organização.
- Fase 5: Monitorização e otimização - Monitorizar o desempenho e otimizar a solução com base no feedback
Resultados esperados
• Maior disponibilidade do sistema - Alcance quase 100% de tempo de atividade.
- Gestão eficiente de falhas - Deteção e resolução mais rápidas de problemas.
- Monitorização de desempenho melhorada - Informações em tempo real sobre o desempenho do sistema.
- Gestão proactiva de incidentes - Prever e evitar potenciais incidentes.
- Melhoria Contínua - Aproveitamento de dados históricos para otimização contínua.
- Interoperabilidade perfeita - Integração suave em vários domínios de TI.
- Orquestração eficaz - Alterações simplificadas do sistema em massa.
- Planeamento optimizado da rede - Conceção e otimização da rede com base em dados.
- Análise abrangente do desempenho - Monitorização em tempo real e acompanhamento de KPI com ferramentas de visualização.
KPI operacional crítico da solução GSA
A solução abordará vários KPIs operacionais SRE cruciais para garantir um desempenho e fiabilidade ideais, incluindo
- Tempo médio de deteção (MTTD): O tempo médio necessário para detetar um incidente. A redução do MTTD ajuda na identificação mais rápida dos problemas.
- Tempo médio de resolução (MTTR): O tempo médio necessário para resolver um incidente depois de este ter sido detectado. Um MTTR mais baixo indica capacidades de resolução mais rápidas.
- Indicadores de nível de serviço (SLIs): Métricas que medem o desempenho de um serviço (por exemplo, latência, taxa de erro, rendimento).
- Objectivos de nível de serviço (SLOs): Metas estabelecidas para SLIs que definem níveis de desempenho aceitáveis.
- Acordos de nível de serviço (SLAs): Acordos formais que estabelecem expectativas para o desempenho do serviço entre provedores de serviços e clientes.
- Taxa de falha de mudança: A porcentagem de mudanças que resultam em serviço degradado ou exigem correção. Taxas mais baixas indicam mudanças mais bem-sucedidas.
- Orçamento de erros: A quantidade permitida de tempo de inatividade ou erros dentro de um período específico, derivado de SLOs.
- Taxa de incidentes: A frequência de incidentes que ocorrem dentro de um período de tempo específico. A monitorização desta taxa ajuda a compreender a estabilidade do sistema.
- Disponibilidade: A percentagem de tempo em que o sistema está operacional e disponível. A elevada disponibilidade é crucial para a satisfação do utilizador.

Critérios de avaliação
O sucesso da PoC será avaliado com base em:
- Tempo de funcionamento do sistema - Medição da disponibilidade do sistema.
- Precisão da priorização de alarmes - Redução de falsos positivos e classificação precisa de alarmes.
- Tempo de resolução de falhas - Redução do tempo necessário para resolver falhas.
- Feedback do utilizador - Feedback dos administradores e utilizadores do sistema.
- Métricas de desempenho - Melhoria dos principais indicadores de desempenho (KPIs), como MTTD, MTTR, SLIs, SLOs, SLAs, taxa de falha de alteração, orçamento de erros, taxa de incidentes e disponibilidade.
- Interoperabilidade - Integração e utilização bem sucedidas em vários domínios de TI/rede.
- Eficácia da orquestração - Eficiência e precisão das alterações do sistema em massa com tolerância zero ao tempo de inatividade
- Otimização do planeamento da rede - Qualidade dos conhecimentos e melhorias no planeamento da rede.
- Visualização e análise - Eficácia da monitorização em tempo real e acompanhamento de KPI através de ferramentas de visualização
